size, speed and order tradeoffs
tldr
intro to cache friendly programming supported by a cpp code repo with timing graphs
modern cpu
modern computers are driven by CPUs which already have optimisations happening for you in the hardware. writing faster (low latency) code requires that you know what speedups are already happening and do what you can to facilitate them or at least that you dont scupper them.
ram is cheap
dynamic ram is cheap so machines can have lots of it but its not very fast. faster types of ram exist and are situated closer to (or within) the circuits of the CPU itself. even though it works faster, commodity machines cant have much of it, because this kind of ram is much more expensive to manufacture.
cacheing
when the cpu reads a memory address it first checks the cache, if the address is present in the cache then it reads from there. otherwise it tries the next level cache and so on until it reads from the memory which is much slower. once the address is found it copies this to the higher level cache(s) for faster access next time.
this process continues for all reads and writes potentially speeding up execution. it causes speedup because programmes and data are usually arranged so that related items are near each other in memory.
consider the members of a single instance of a class, they are adjacent. also consider the elements of an array, passing over it in sequence means the neighboring elements are cached.
conversely consider a dynamic data structure like a linked list on the heap. if the structure is very dynamic and has been edited, then each element will likely be at an unrelated memory address. in this case loading an item wont load its neighbors, so the cache has little effect and the algorithm runs slower.
cache architecture and tools
in the following image the CPUs are grey with the various caches sitting between them and the ram at the top.
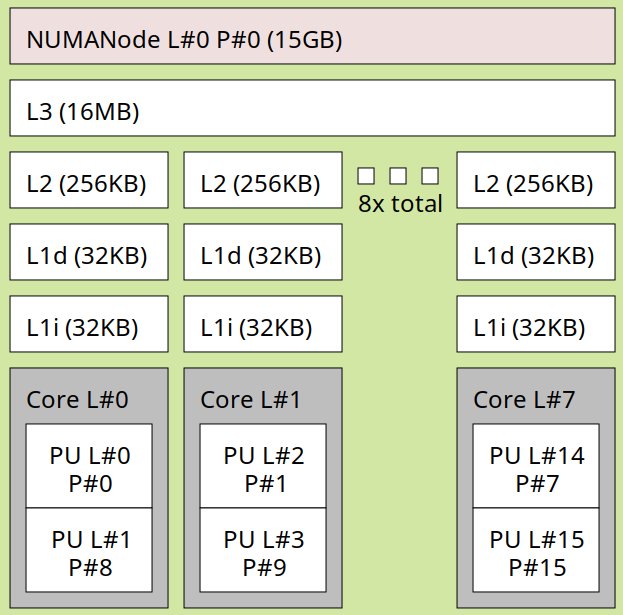
each processor has its own L1 and L2 caches and they all share a L3 cache. you can generate a similar image for your machine by installing hwloc and using lstopo.
sudo apt install hwloc
lstopo -p
using getconf on linux we also can learn the various parameters of the CPU architecture.
getconf -a | grep CACHE
the machine im woking on now outputs the following
LEVEL1_ICACHE_SIZE 32768
LEVEL1_ICACHE_ASSOC
LEVEL1_ICACHE_LINESIZE 64
LEVEL1_DCACHE_SIZE 32768
LEVEL1_DCACHE_ASSOC 8
LEVEL1_DCACHE_LINESIZE 64
LEVEL2_CACHE_SIZE 262144
LEVEL2_CACHE_ASSOC 4
LEVEL2_CACHE_LINESIZE 64
LEVEL3_CACHE_SIZE 16777216
LEVEL3_CACHE_ASSOC 16
LEVEL3_CACHE_LINESIZE 64
LEVEL4_CACHE_SIZE 0
LEVEL4_CACHE_ASSOC
LEVEL4_CACHE_LINESIZE
decypher
lets decipher some of this
there are three levels of cache, which work in a cascade with reads and writes working through each cache out to ram.
- ICACHE this is the instruction cache
-
DCACHE is the data cache
- the L1 Cache is 32 KB
- the L2 Cache is 256 KB
- the L3 Cache is 16 MB
in all cases the caches have a LINESIZE (the size of the read write unit) which is 64 bytes which means when a part of memory is loaded
do your own tests
on github i have a repo with two experiments the source is avaiable so you can run on your own machine to see how they work for you.
same work over larger data area
in this experiment we have a large array on the heap, we access it in order, then test again several times, with successivly larger arrays. each time however we also increase the stride or skip of the traversal so when the array is 64x larger we skip 64 and then overall the same work is being done.
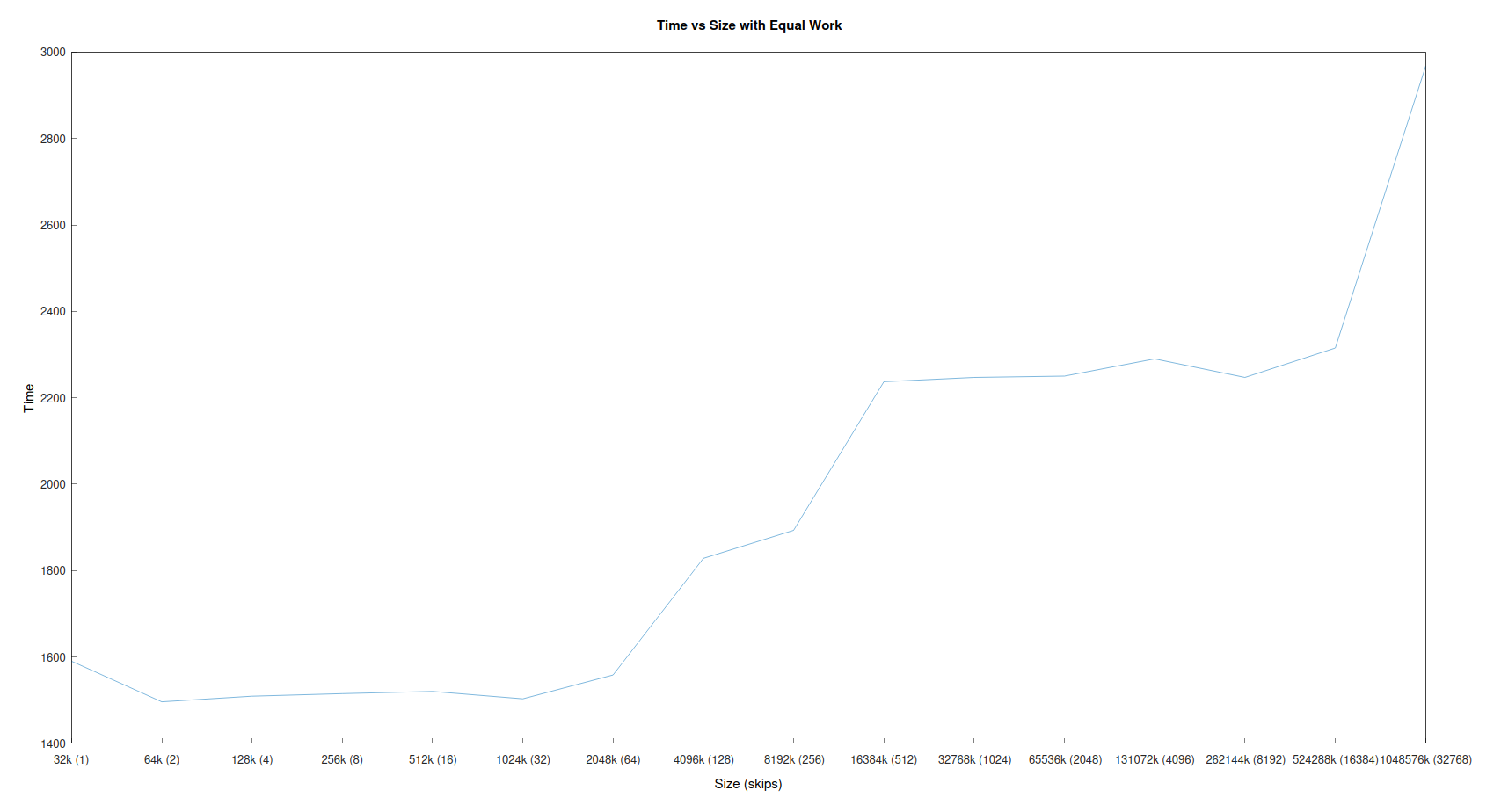
take a look at the time taken to carry out the traversal. the larger arrays take longer and longer though the same work is being done. this is because many fewer cache hits are occuring in the larger arrays so the data has to be read from a slow place.
accessing arrays in two different ways
in this experiment we have a moderately sized array and are accessig it in two different ways. in row first order then in column first order.
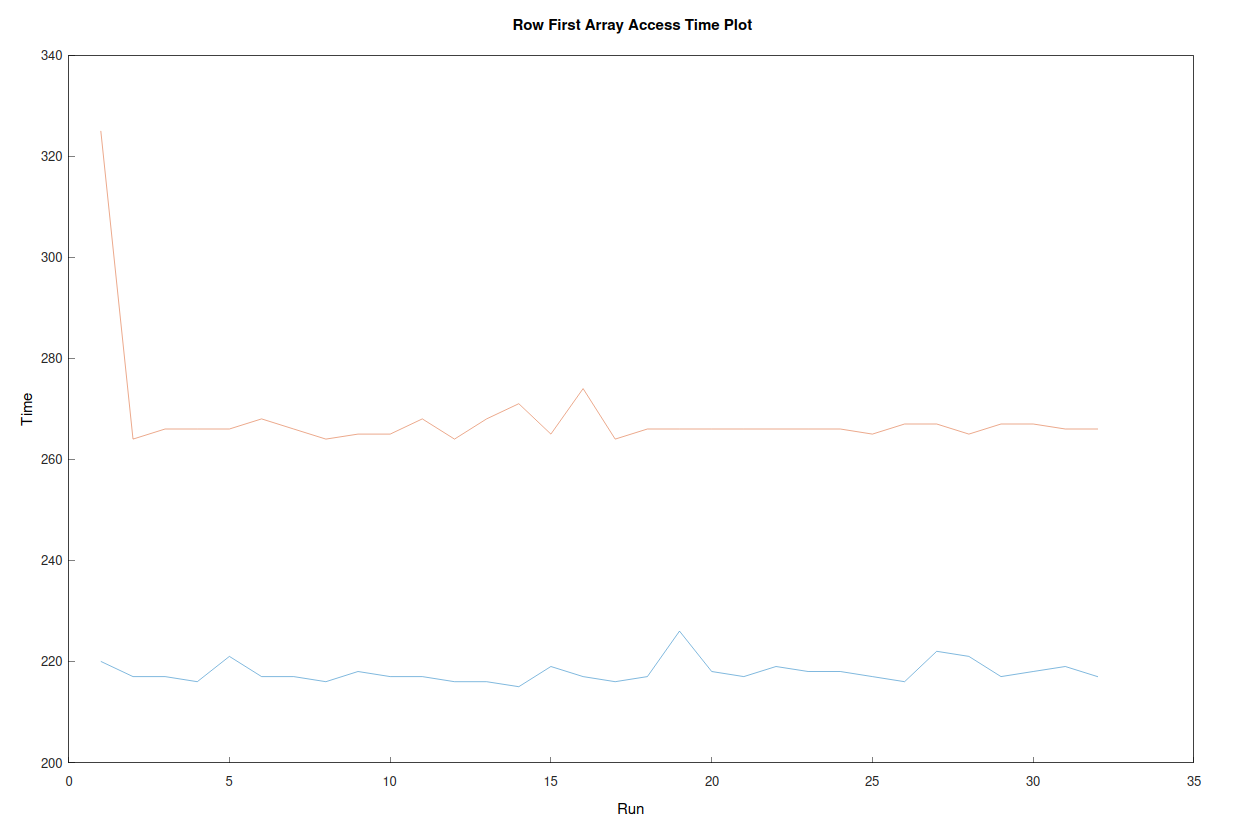
as you can see there is a surprising time difference between the two. again the order we read from an array has an impact and you can see clearly the same array read in a different order allows us to do work quicker.
takeaways
when successful we call this a cache hit, unsuccessful a cache miss. if a programmer wishes to make their code run faster on modern processors one way to achieve this is to write in a way that has many more cache hits.
to write code that is more friendly to cached cpus we have a few options.
- wherever possible use the stack rather than the heap.
- when a varible is to be used, it it is closely related to another, then place them within 64 bytes of each other.
- construct your containers so when passed over in order the neighboring are increases the chance of cache hits by being close in memory, perferably adjacent. arrays = best, vectors = good, linked lists = bad.
- if you have an algorithm which is to run fast, then try to make it fit within the ICACHE (32k)
- if you have large amounts of data and code perhaps consider an appraoach which keeps it all within one of the larger caches for the duration of its need.